柏聯科技-CCTV影像辨識怎麼進化?傳統AI vs 生成式AI 差異一次看懂

除了科技執法能抓違規車輛,現在連「亂丟垃圾」這類行為,也能靠 AI 自動辨識、即時舉發!
許多人不知道,CCTV 監控系統早已不只是錄影工具,搭配 AI 影像辨識後,能主動辨識違規行為,例如違規停車、逆向行駛、誤闖閘道車輛等。這些都是屬於固定型態事件,適合使用「分辨式 AI」(也常被稱為傳統 AI)來處理。
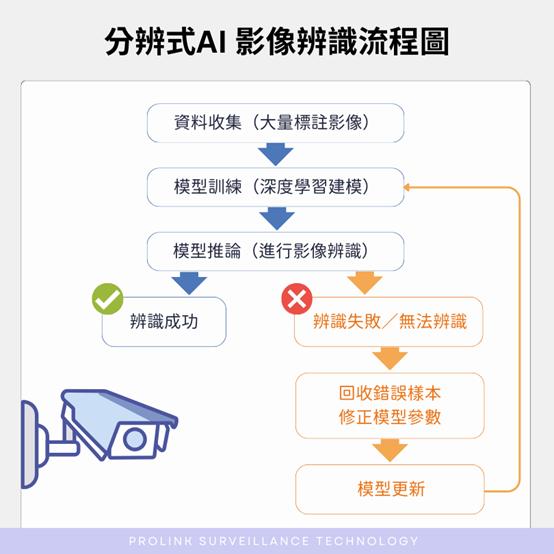
分辨式 AI 的運作流程
所謂「分辨式 AI」(通常基於 CNN 卷積神經網路),就是透過大量的標註資料來進行訓練,流程如下:
STEP 1. 資料收集:收集大量影像,並一一標註出物件種類(例如:車輛、人、物品、動物等)
STEP 2. 模型訓練:透過深度學習建立模型
STEP 3. 模型推論:AI 依據訓練結果進行實際辨識
STEP 4. 錯誤修正:若辨識失敗或無法辨識,需回收錯誤樣本並修正模型參數
STEP 5. 模型更新:再次訓練模型,進行下一次推論(如此循環)
分辨式 AI 就像是一個經過密集訓練的識別員,靠大量的圖片學會「這是什麼、那不是什麼」,例如能準確辨認這是貨車、那是腳踏車,車牌是什麼、車子是什麼顏色。
但如果遇到它「沒學過的」情境,就容易出錯或無法判斷。
為什麼無法辨識「亂丟垃圾」這種非固定事件?
但如果遇到非固定型態的事件呢?像是「亂丟垃圾」,每次出現的狀況都不一樣──可能是粉紅色大包垃圾、黑色小包垃圾,甚至是一張廢棄椅子;有人會直接丟,有人會偷偷放。這些都不屬於邏輯清楚、容易辨識的行為,對傳統 AI 來說根本無從判斷。
生成式 AI 如何解決傳統AI的盲點?
這時,生成式 AI (GenAI)就派上用場了!它不像分辨式 AI 一樣只能比對是否「看過」的樣本,而是能根據情境、狀態和過往經驗做出推理。
舉凡打架、車禍、機具倒塌等「沒有固定樣貌」的突發事件,畢竟每個人打架時的動作姿勢都不同,車禍的情況也可能千變萬化,生成式 AI 都能從畫面中抽取線索,自主判斷。
傳統 AI 像保全,生成式 AI 像主管
如果要比喻,分辨式 AI 就像是一位拿著厚厚訓練手冊的保全,手冊裡記錄著所有「教過」他的可疑物件和動作──只要遇到沒學過的,他就會說:「這我沒看過,無法判斷。」
而生成式 AI 更像是一位經驗豐富、能靈活應變的主管。
即使你沒逐條教他怎麼做,他也能從場域狀況推敲出異常行為。像是新聞中常見的機具倒塌事件,其實在倒塌前往往會先出現傾斜或重心不穩的徵兆。生成式 AI 能即時捕捉這類異常動態,提早預警異常行為。
如下圖所示,這是擷取自新聞報導的一起工地吊車翻覆事件,從傾斜到倒塌僅僅幾秒。值得注意的是,即便我們僅針對「稍微傾斜」的瞬間,透過自然語言詢問「這設備是否異常?」,生成式 AI 仍能依據單張畫面,自主判斷出吊車懸掛於泥土地、傾斜不穩,並理解這樣的情境可能對操作人員與現場安全造成風險。這正展現了生成式 AI 不需明確標註、不需多角度比對,就能從整體情境推理出潛在危機,並及早預警異常。
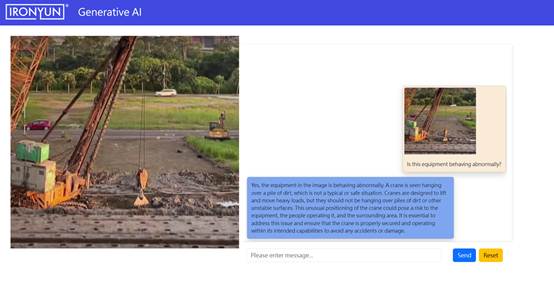
▲【最早情況】圖一:設備異常懸吊中,出現不穩徵兆
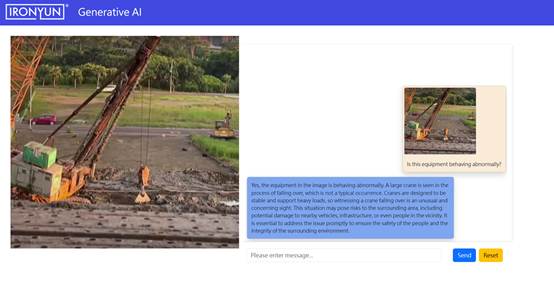
- 圖二:設備失去平衡,傾倒開始
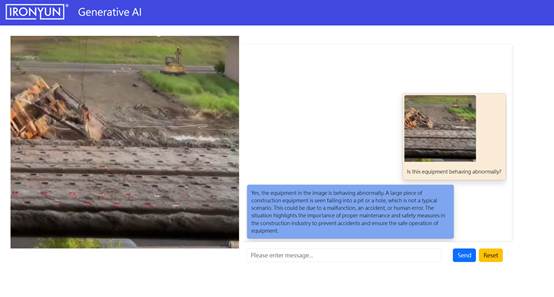
- 圖三:設備完全翻覆,事故發生
本地端運行的優勢:不靠雲端,快速又安全
此外,並不是所有 AI 都像 ChatGPT 或 Gemini 一樣仰賴雲端運算。
在石化廠、工地、港口這類網路常常不穩的地方,如果辨識還要傳資料到雲端等結果,常常還沒警報響起,人就已經出事了。
這也是 VAIDIO 生成式 AI 本地端運行的最大價值:
不必上傳資料、不等雲端回傳,AI 自己看得懂直接判斷、即時反應
資料不外流,安全性與即時性兼顧!
傳統AI vs 生成式AI 差異
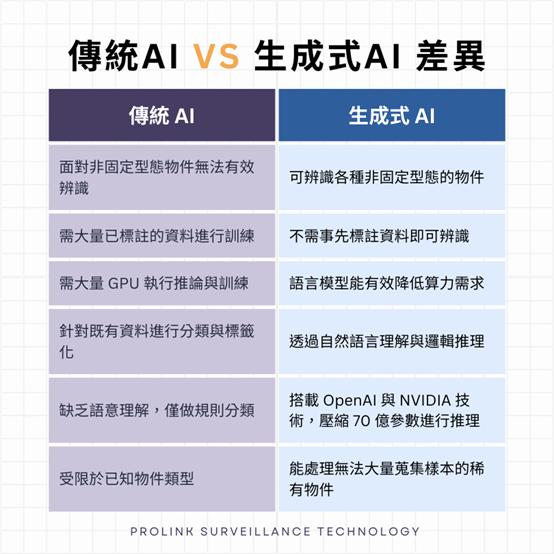
傳統 AI
面對非固定型態物件無法有效辨識
需大量已標註的資料進行訓練
需大量 GPU 執行推論與訓練
針對既有資料進行分類與標籤化
缺乏語意理解,僅做規則分類
受限於已知物件類型
生成式 AI
可辨識各種非固定型態的物件
不需事先標註資料即可辨識
語言模型能有效降低算力需求
透過自然語言理解與邏輯推理
搭載 OpenAI 與 NVIDIA 技術,壓縮 70 億參數進行推理
能處理無法大量蒐集樣本的稀有物件